如何低成本激活海量用户行为数据价值?NoETL 语义编织实践指南
摘要
NoETL 语义编织是一种全新的数据架构范式,通过在现有数据湖仓的明细层之上构建一个统一、中立的语义层,实现业务逻辑与物理底表的彻底解耦。它通过声明式指标定义、自动化查询生成与智能物化加速三大支柱,从根本上解决传统 ETL 模式下的口径混乱、响应迟缓与成本高昂问题,让业务人员实现任意维度的秒级自助分析,并为 AI 智能体提供确定性的数据上下文。本文面向数据架构师与 CDO,提供一套从认知到落地的完整实践指南。
每天,数亿条用户点击、浏览、停留的埋点数据,正源源不断地涌入企业的数据湖仓。然而,这些本该驱动精准营销、产品迭代和体验优化的“数据原油”,却因传统数据供给模式的瓶颈,长期沉睡,沦为吞噬存储与计算成本的“负资产”。
现实更为严峻:企业湖仓数据冗余平均在 5 倍以上,而专业数据人才的缺口高达 200 万。这意味着,企业正陷入 “数据越多,价值越难释放” 的怪圈。当业务部门急需一个“高价值用户转化漏斗”的分析时,数据团队往往需要排期数周,通过重复开发宽表来响应,最终产出口径不一、维度固化的报表,无法满足灵活探查的需求。
问题的根源,在于传统以人工 ETL 和物理宽表为核心的数据供给模式,已无法平衡 “业务灵活性”、“口径一致性”与“性能成本” 的“不可能三角”。而 AI 智能体(Agent)时代的到来,以其发散性、秒级响应的问数需求,彻底击穿了这套勉力维持的旧体系。
激活海量用户行为数据价值的关键,在于一场从“过程驱动”到“语义驱动”的范式重构——引入 NoETL 语义编织架构。
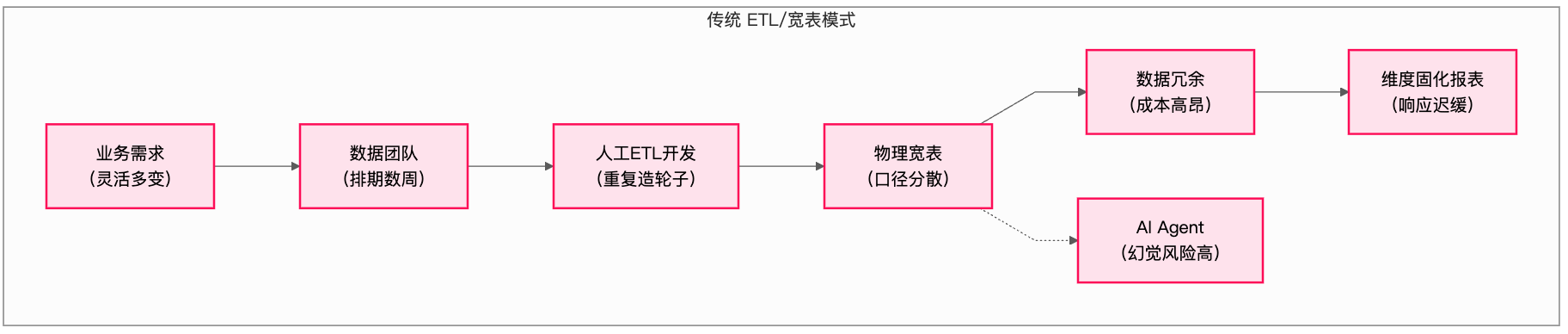
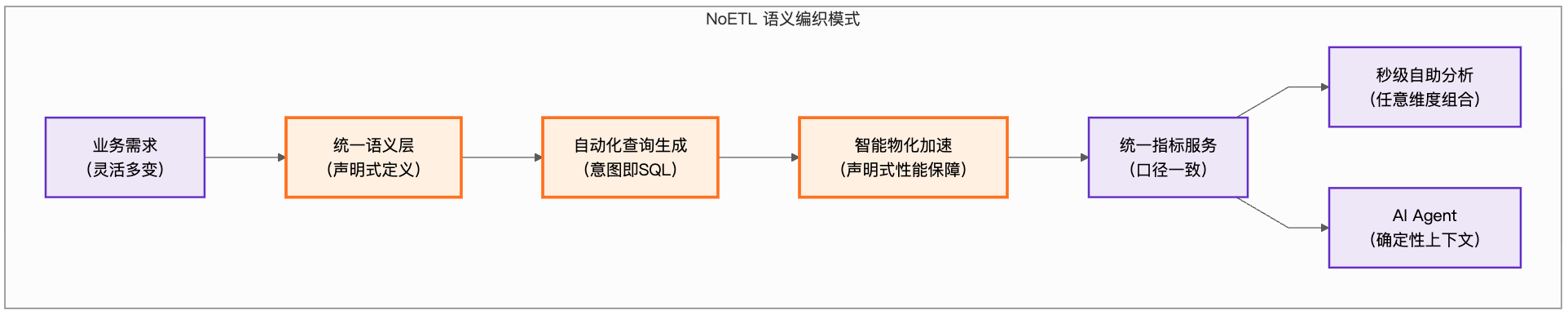
前置条件:认清传统数据供给模式的“不可能三角”
在深入解决方案前,我们必须正视当前架构的根本性矛盾。这个“不可能三角”具体表现为:
业务灵活性:营销、产品等一线部门希望像使用搜索引擎一样,自由组合“渠道”、“用户标签”、“时间周期”等维度,进行探索性分析。但在宽表模式下,维度组合是预定义的,任何未预设的分析路径都需要重新开发。
口径一致性:管理层要求“GMV”、“活跃用户”等核心指标在全公司有且仅有一个权威定义。然而,指标逻辑被硬编码在分散的 ETL 脚本和物理宽表中,微小的逻辑差异导致报表间“数据打架”成为常态。
性能与成本:数据团队需要在有限的预算内保障查询秒级响应。为此,他们不得不预建大量宽表和汇总表(ADS层),导致相同明细数据被反复加工存储,形成巨大的冗余和浪费,陷入“为保障性能而推高成本”的恶性循环。
这套依赖人力的“人工预计算”范式,在数据量和分析需求激增的今天,已成为数据价值释放的主要瓶颈。解决问题的出路,不是在这个三角中继续做痛苦的取舍,而是通过架构革新,打破三角本身。
第一步:架构重构——引入 NoETL 语义编织层
解决问题的起点,是将 “业务语义” 与 “物理底表” 彻底解耦。这类似于软件开发从汇编语言(直接操作硬件)演进到高级语言(声明业务逻辑)。
NoETL 语义编织 的核心,是在企业的公共明细数据层(DWD)与上游的消费应用(BI、AI Agent、业务系统)之间,构建一个独立、统一、具备实时计算能力的 语义层(Semantic Layer)。
逻辑层(做什么):业务分析师在语义层中,通过声明式的方式,用业务语言定义指标(如“近 30 天高价值用户留存率”)、维度及其关联关系。他们无需关心数据存储在哪里、表如何关联。
物理层(怎么做):平台的 语义引擎 自动将逻辑定义“编译”为面向底层数据湖仓(如 Snowflake, BigQuery)优化过的高效 SQL 执行计划。无论是实时查询明细,还是智能路由到加速表,都由系统自动完成。
这种解耦带来了 “无头化(Headless)” 与 “中立性”。数据不再为某个特定的 BI 报表加工,而是成为一种标准化的服务。无论是 BI 工具,还是未来的 AI 应用,都通过统一的 API/JDBC 接口消费同一份经过治理的“逻辑真理”。
第二步:能力建设——部署具备三大支柱的指标平台
一个合格的 NoETL 语义编织平台,必须具备以下三大核心能力,缺一不可:
1. 统一语义层:构建虚拟的业务事实网络
平台允许用户在未物理打宽的 DWD 表之上,通过界面化配置,声明式地定义表与表之间的关联关系(如用户表与行为事件表通过 user_id 关联)。由此,在逻辑层面构建出一张覆盖全域的 “虚拟大宽表”,业务人员可在此基础上进行任意拖拽分析。
2. 自动化查询生成:意图即 SQL
当用户拖拽指标或 AI Agent 提出自然语言问题时,平台的语义引擎能实时解析分析意图,自动生成高效、优化的查询 SQL,自动处理复杂的多表 JOIN、去重和跨层级计算,实现数据获取的零门槛。
3. 智能物化加速:基于声明的性能保障
这是区别于传统逻辑视图的关键。平台提供 “声明式物化” 能力:
管理员声明:基于业务需求,声明需要对哪些指标和维度组合进行加速,以及数据时效性要求(如 T+1)。
系统自治:平台根据声明,自动设计物化视图、编排 ETL 任务依赖并运维。
透明路由:查询时,引擎自动进行 SQL 改写,让查询命中最佳的物化结果,实现百亿级数据的秒级响应。尤其关键的是,其物化引擎支持对去重计数、比率类等复杂指标进行上卷聚合,突破了传统物化技术的限制。
第三步:实施落地——采用“存量挂载”与“增量原生”混合策略
引入新范式无需“推倒重来”。我们推荐采用分阶段的混合策略,平滑演进,保护既有投资:
存量挂载(保护投资):对于现有逻辑稳定、性能尚可的物理宽表,直接将其接入语义层,映射为“逻辑视图”并注册指标。实现零开发成本下的统一服务出口。
增量原生(遏制新债):对所有新产生的分析需求,尤其是来自 AI Agent 的灵活问数,坚决采用“原生”模式。直接基于 DWD 明细层,通过语义层定义指标,由平台自动化处理计算与加速,从源头杜绝新宽表的产生。
存量替旧(优化成本):在平台能力得到验证后,逐步识别并下线那些维护成本高、逻辑复杂的“包袱型”旧宽表,将其逻辑迁移至语义层,释放计算资源。
一个典型的推广路径分为四个阶段:战略筹备与灯塔选择 -> 价值验证与能力内化 -> 全面推广与组织建设 -> 生态融合与价值深化。核心是从一个痛点明确的业务场景(如“营销活动分析”)切入,快速交付可感知的价值,建立内部信心后再规模化推广。
第四步:价值深化——从统一分析到赋能 AI 智能体
当统一的指标语义基座建成后,其价值将超越传统 BI,深度赋能 AI 场景:
为 AI 划定“认知围栏”:语义层提供的结构化、业务友好的指标与维度元数据,是 RAG(检索增强生成)的优质语料。AI Agent 不再需要直面晦涩的物理表 Schema 去“猜测”SQL,而是通过 NL2Metrics(自然语言转指标查询) 模式,调用标准的语义 API(如
GetMetric(name=”毛利”, filter={region:”华东”})),从根本上降低幻觉风险。提供深度分析工具:语义层内置的 明细级多维度归因 等模块,可通过 API 被 AI Agent 调用。当业务指标波动时,AI 能自动、即时地分析出是哪个维度(地区、渠道)下的哪个具体值(某个产品)贡献了主要变化,实现从“看数”到“归因”的智能决策闭环。
实现双模驱动:底层同一套语义基座,向上同时支撑 BI 的“稳”(固定报表、高精度、秒级呈现)与 AI 的“活”(灵活探查、自然交互、智能归因),无需为 AI 单独建设数据管道。
避坑指南:甄别“真伪”NoETL 语义编织平台
市场概念纷杂,选型时请重点考察以下四个维度:
计算内核:是“静态逻辑目录”还是“动态计算引擎”?真平台必须支持在未打宽的 DWD 上构建“虚拟事实网络”,并支持通过配置定义跨表聚合、二次聚合、比率留存等复杂指标,而非只能做简单聚合。
性能机制:智能物化是“全自动”还是“基于声明”?真平台应允许管理员声明加速策略,由系统自动完成物化任务的创建、运维和查询路由,并支持不可累加指标(如去重计数)的物化上卷。
架构属性:是“BI 附属品”还是“中立开放基座”?真平台应通过标准 Restful API 和 JDBC 接口提供服务,能与任何 BI 工具(如 Tableau、Power BI 通过 JDBC)、业务系统或自研 AI Agent 无缝集成,避免厂商锁定。
AI 适配度:是“Schema 投喂”还是“语义增强”?真平台应提供结构化的语义元数据(指标口径、血缘、业务限定),支持 NL2Metrics 和 Function Calling,为 AI 提供精准的业务上下文,而非仅仅暴露原始表结构。
成功标准:如何衡量数据价值是否被真正激活?
数据价值的激活应是可量化、可感知的。成功落地后,企业应在以下三个维度看到显著改善:
业务敏捷性:临时性、探索性的数据分析需求,平均响应时间从“周级”缩短至“分钟级”,业务自助用数比例大幅提升。
成本可控性:通过消除冗余的 ETL 加工和物理宽表,数据仓库的存储与计算成本得到显著优化(实践案例中常见 20%-30% 的下降)。
决策精准性:基于全公司统一的指标口径,数据驱动的洞察更加可信。结合明细级归因能力,业务行动(如渠道优化、产品迭代)的效果可衡量、可归因,决策闭环速度加快。
案例印证:某头部券商引入 NoETL 语义编织平台后,在一条核心业务线上,IT 仅需维护 10 张公共层模型和 100 个原子指标,即可支撑业务人员使用超过 300 个维度进行灵活组合分析,将指标开发交付周期从两周以上缩短到分钟级,并实现了指标口径的 100% 一致。
FAQ
Q1: 我们已经用了现代云数仓,为什么还需要 NoETL 语义编织?
现代云数仓(如 Snowflake、BigQuery)解决了存储和计算的弹性问题,是强大的“引擎”。但业务灵活分析的需求,仍然需要通过人工开发大量宽表来满足,这导致了“最后一公里”的口径混乱和成本浪费。NoETL 语义编织是在这些强大引擎之上,构建统一、敏捷的“业务语义层”和“自动变速箱”,让好引擎能持续、高效地产出可信、好用的数据。
Q2: NoETL 是不是意味着完全取消 ETL?历史宽表怎么办?
NoETL 并非取消 ETL,而是改变其主体和模式。物化加速本身也是一种 ETL,但其策略由管理员声明,执行由系统自动完成。对于历史宽表,建议采用“存量挂载”策略接入,保护投资;对所有新需求,坚决采用“增量原生”,由系统自动化智能物化,无需人工开发新宽表。
Q3: 引入 NoETL 语义编织,对现有数据团队有什么影响?
这是积极的角色转型。数据工程师将从重复、低价值的 SQL 脚本编写和 ETL 运维中解放出来,转向更具战略性的工作:设计与优化企业级语义模型、保障数据供应链质量、配置与优化物化策略(FinOps)、以及赋能业务人员。平台通常提供直观界面,辅以针对性培训,团队可以较快适应新角色,提升整体价值。
Key Takeaways(核心要点)
范式革新:NoETL 语义编织通过 “逻辑与物理解耦”,构建统一语义层,是解决传统数据供给“不可能三角”的根本性架构革新。
核心能力:真正的平台必须具备 统一语义建模、自动化查询生成、声明式智能物化加速 三大支柱,尤其要支持复杂指标的物化上卷。
落地路径:采用 “存量挂载 + 增量原生” 的混合策略,从灯塔场景切入,小步快跑,实现平滑演进与价值快速兑现。
未来价值:统一的语义基座不仅是提升 BI 效率的工具,更是企业构建 AI-Ready 数据底座、实现“BI稳”与“AI 活”双模驱动的关键基础设施。
衡量标准:成功与否看三点:业务分析响应是否进入“分钟级”、存算成本是否显著下降、数据驱动的决策是否更精准可行动。

