自研指标平台是大坑?80% 企业选择采购 NoETL 自动化指标平台
摘要
面对传统 ETL 开发效率低下、指标口径混乱的行业顽疾,许多企业选择自研指标平台,却普遍低估了其工程复杂度。真正的挑战在于构建一个能实时解析业务语义、智能保障查询性能并开放对接异构应用的“动态计算引擎”。本文基于行业实践与架构分析,揭示自研面临的三大“鬼门关”,并通过总拥有成本(TCO)对比,论证采购成熟的 NoETL 自动化指标平台(如 Aloudata CAN)是追求确定性回报的理性决策,旨在为数据架构师与 CDO 提供选型参考。
认知误区:你以为在做“字典”,实际需要打造“引擎”
企业启动自研指标平台的初衷通常是解决“口径乱”的问题,希望建立一个统一的指标目录或“字典”。然而,在 AI 驱动的数智化运营时代,业务对数据的灵活性要求呈指数级增长。一个简单的指标目录,无法支撑业务人员“任意维度、任意筛选”的自助分析,更无法让 AI 智能体(Agent)理解并调用。
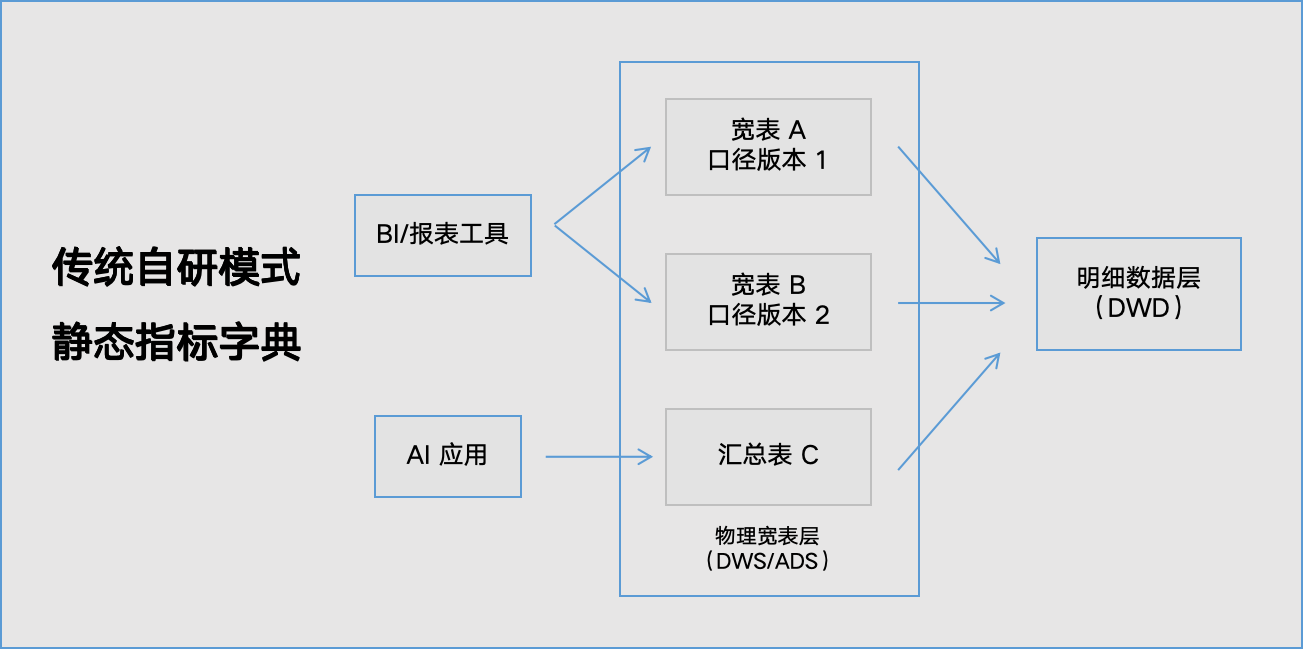
“传统 ETL 通过宽表和汇总表交付指标的模式,导致了大量指标的重复开发,造成企业在存储和计算上的巨大浪费。” —— Aloudata CAN 产品白皮书
问题的本质在于,支撑现代数据分析的并非一个静态的“字典”,而是一个能实时工作的“引擎”。这个引擎需要具备:
语义解析能力:理解业务术语(如“有效销售额”)背后的复杂计算逻辑(SUM(订单金额) - SUM(退款金额))。
动态计算能力:在不预建物理宽表的前提下,实时关联多张明细表,生成“虚拟业务事实网络”。
性能保障能力:通过智能化的物化加速,确保对海量明细数据的查询也能获得秒级响应。
自研项目往往始于对“统一口径”的朴素追求,却最终陷入构建一个企业级“语义计算引擎”的深水区,其技术复杂度和资源需求远超初期规划。
鬼门关一:语义解析——从“静态表”到“动态虚拟宽表”
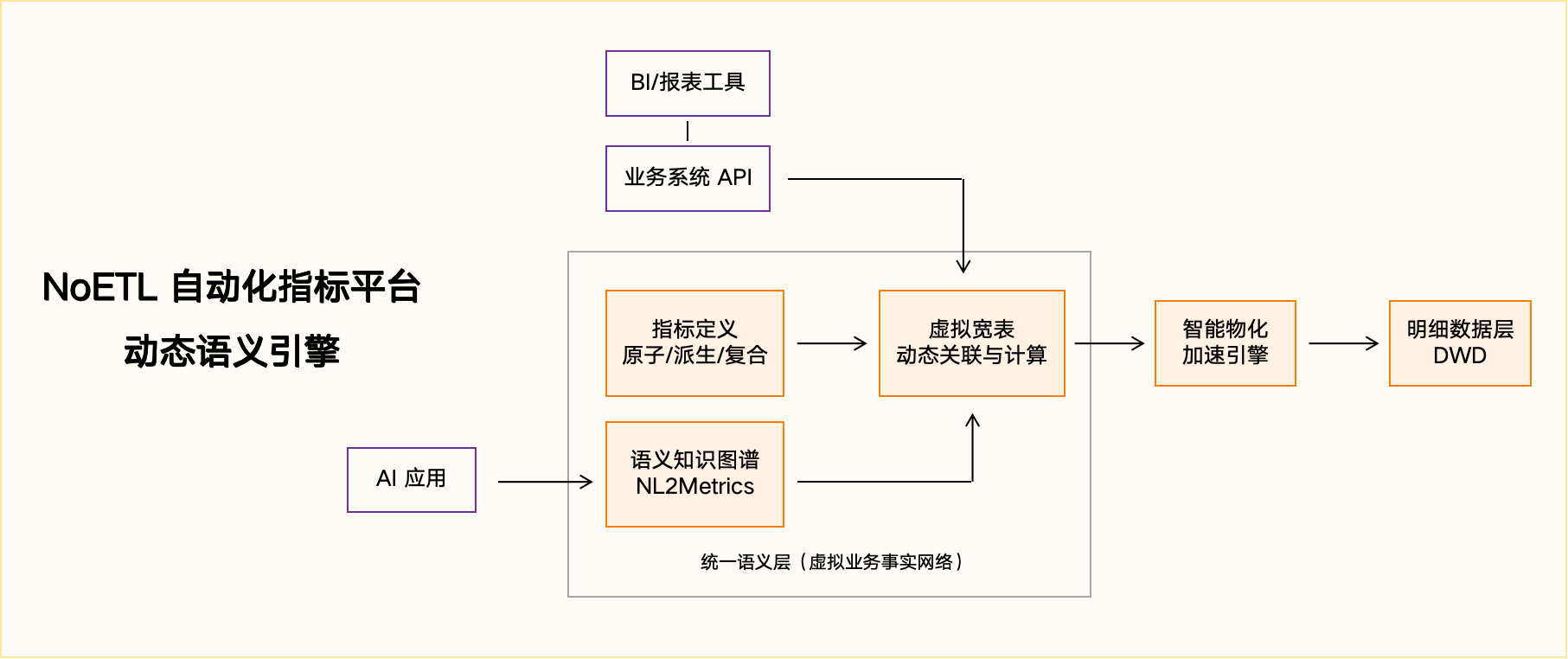
这是自研面临的第一道技术鸿沟。传统方式通过 ETL 工程师编写 SQL,将业务逻辑固化在物理宽表(DWS/ADS)中。而 NoETL 语义编织要求平台构建一个“统一语义层”,在不进行物理打宽的前提下,通过声明式建模,让系统能实时理解并关联跨多张明细表(DWD)的业务逻辑,形成“虚拟业务事实网络”。
这要求自研团队具备编译原理、查询优化和复杂业务抽象能力,而非简单的 SQL 封装。具体挑战包括:
逻辑关联的动态解析:如何让系统理解“订单表”的“客户 ID”与“客户维度表”的“客户 ID”在业务上等价,并能处理多通路等复杂场景。这需要设计一套元数据模型来声明和管理表间关联关系。
复杂指标的函数化封装:如何将“近 30 天消费金额 >5000 的客户数”这类业务需求,配置化为可复用的语义函数(如跨表限定、指标维度化、二次聚合),而无需为每个需求手写数百行 SQL。这本质上是构建一个面向业务人员的“高级查询语言”及其编译器。
NL2Metrics的意图理解:若想对接 AI,还需构建让大模型能理解的“语义知识图谱”,实现从自然语言到指标调用的精准转换(NL2Metrics),从根源上根治数据幻觉。这需要将业务指标、维度、限定条件等语义元数据结构化,并提供标准的 Function Calling 接口。
自研团队需要从“SQL 脚本执行者”转变为“语义编译器设计者”,这是一个质的飞跃。
鬼门关二:智能物化——从“人工运维”到“系统自治”
即使解决了语义解析,面对企业百亿级的明细数据,如何保障查询的秒级响应?传统做法是数据工程师基于经验,手动创建和维护大量的物化视图(加速表)。但这种方式成本高昂、响应滞后,且极易形成新的数据冗余。
NoETL 平台的智能物化加速,其核心并非取消 ETL,而是将其升级为一种由“声明式策略”驱动的自动化性能服务。自研实现这一能力的难点在于:
物化策略的自动生成与优化:如何基于用户对指标和维度的“加速声明”,结合数据分布和查询历史,自动设计出存储成本与查询性能最优的物化方案,并支持去重计数、比率类等复杂指标的上卷。
查询的透明改写与路由:如何让用户的查询请求(无论是来自 BI 拖拽还是 AI 调用)无感知地自动路由到最优的物化结果上,并完成底层 SQL 的透明改写,这对查询优化器的要求极高。
口径变更影响的全面分析:如何在指标口径变更时自动识别并提示所有下游影响,辅助用户根据变更影响告警进行物化任务重建和数据回刷操作,这对数据血缘解析有着极高的要求。
“通过智能物化加速确保十亿、百亿级明细数据的秒级查询响应。” —— NoETL 指标平台白皮书
这要求自研团队不仅精通数据库内核优化,还需具备平台级的资源调度与元数据解析与管理能力。
鬼门关三:生态适配——从“孤岛工具”到“中立基座”
指标平台的终极价值在于被消费。企业内往往存在多种 BI 工具(如 Tableau、Power BI)、业务系统和新兴的 AI 应用。自研平台极易陷入为某个特定前端(如某个自研报表系统)深度定制的陷阱,成为一个新的“数据孤岛”。
真正的指标平台必须是中立的“数据中枢”,其挑战在于:
标准化接口设计与实现:提供稳定、高性能的 Restful API 和成熟的 JDBC 驱动,确保下游各类应用能无差别、高性能地调用指标服务。
治理规则的内嵌与强制执行:将企业的数据安全策略(行列级权限)、审批流程等治理要求,平台化、内嵌化到指标的生产和消费链路中,从技术上保障“One Truth”的落地,而非依赖人工监督。
与现有数据湖仓的平滑集成:无需推翻重来,能通过标准连接器对接企业已有的各类数据湖仓,实现对存量宽表的“挂载”与新需求的“原生”建模混合策略,保护既有投资。
生态适配能力决定了平台是企业长期演进的“基石”还是又一个短命的“项目”。
TCO 账本:自研的“隐形高利贷”与采购的“确定性回报”
决策必须超越初始采购费用,基于总拥有成本(TCO)进行理性分析。自研的初始开发成本只是冰山一角,后续高昂的持续维护、升级、扩容成本,以及因效率低下导致的业务机会成本,构成了“隐形高利贷”。
| 成本维度 | 自研模式 (典型问题) | 采购 NoETL 平台 (典型收益) |
|---|---|---|
| 人力成本 | 组建并长期供养一支精通数据架构、编译原理、分布式系统的顶尖团队,招聘难、流失风险高。 | 将数据工程师从重复 ETL 开发中解放,转向高价值的语义建模与业务赋能,人力结构优化。 |
| 开发与运维成本 | 语义解析能力、动态查询能力、只能物化能力、查询命中与上卷等复杂功能需人工持续设计、开发、调试、运维,复杂度线性攀升。 | 成熟平台实现自动化指标生产、智能物化与查询路由,运维复杂度大幅降低,实现“以销定产”。 |
| 机会成本 | 需求响应慢(周/天级),压抑业务探索,错失市场机会;数据口径混乱,引发决策风险。传统方案探索性分析准确率仅 40%。 | 需求分钟级响应,激活业务自助分析;口径 100% 一致,构建决策信任基石。复杂任务准确率可达 98.75%。 |
根据第三方测试数据,采用成熟的 NoETL 架构平台,可实现 3 年 TCO 降低 45%,需求平均响应时间缩短 90.71%,从“成本中心”转变为“效率引擎”。(来源:相关技术评测报告)
决策矩阵:何时该自研,何时该果断采购?
企业不应一概而论。通过以下决策矩阵,可以清晰判断自身情况:
应果断采购,若:
核心目标是快速实现业务数据化运营与敏捷决策(对应价值主张:C- 协作,A- 自动化)。
缺乏构建并长期维护复杂数据计算引擎(语义引擎、智能物化)的核心技术团队。
需要对接多种 BI 工具和 AI 应用,避免厂商锁定(对应价值主张:N- 标准化)。
希望控制长期 TCO,避免技术债务失控,追求确定性回报。
可谨慎评估自研,若:
拥有极其特殊、封闭且稳定的业务场景,市面产品完全无法满足。
具备世界级的数据系统工程团队,且将自研平台作为核心战略产品投入。
不计较时间与金钱成本,旨在技术积累。
对于绝大多数追求数据敏捷、希望快速获得业务价值的企业,采购成熟的 NoETL 自动化指标平台是明确的最优解。
常见问题 (FAQ)
Q1: 自研指标平台,初期投入大概需要多少人和多长时间?
初期投入严重低估是常见陷阱。要打造一个具备基本语义解析和查询能力的原型,至少需要一个 8-10 人的资深团队(含架构、前后端、数据开发),耗时 6-12 个月。而这仅能达到“可用”水平,距离支撑企业级复杂分析、智能物化和 AI 对接的“好用”阶段,还需持续投入 2-3 年及更多资源进行迭代和运维,总成本远超预期。
Q2: 采购 NoETL 指标平台,如何与我们现有的数据仓库集成?
成熟的 NoETL 平台设计为中立的数据基座。它通过标准连接器直接读取您现有数据仓库的公共明细层(DWD)数据,无需数据搬迁。平台在逻辑层构建语义模型和虚拟宽表,对下游提供统一 API 服务。现有 BI 报表和 ETL 任务可以逐步迁移至新平台消费,实现平滑演进,保护既有投资。
Q3: 如果未来业务变化很大,采购的平台会不会不够灵活?
这正是 NoETL 平台的核心优势——应对变化。其“语义模型驱动”的架构,将易变的业务逻辑(指标口径、维度关联)上浮至可配置的语义层,而将稳定的物理存储与计算下放。当业务变化时,只需在语义层修改或新增配置,无需改动底层 ETL 和物理表。这种解耦设计使平台天生具备极强的业务适应性。
Q4: 如何验证平台真能解决“口径不一致”和“响应慢”的问题?
要求在 POC(概念验证)中设置真实业务场景:1) 口径验证:在平台中统一定义一个核心指标(如“有效销售额”),并确保通过 API 在不同测试报表中调用结果完全一致。2) 性能验证:针对一个涉及多表关联和复杂筛选的灵活分析需求,测试从发起查询到获取结果的端到端响应时间,要求达到秒级。同时,核查厂商提供的同类客户案例中的量化收益数据。
Key Takeaways(核心要点)
本质是引擎,而非字典:自研指标平台的核心挑战是构建具备实时语义解析与智能物化能力的“动态计算引擎”,技术复杂度远超一个静态的指标目录。
三大“鬼门关”难以逾越:语义解析(构建虚拟宽表)、智能物化(系统自治的性能服务)、生态适配(中立的数据中枢)是自研工程实现上的核心难点,需要顶尖的架构与工程团队。
TCO 揭示真实成本:自研的隐性成本(长期维护、机会成本)极高,而采购成熟平台能获得开发提效 10 倍、存算成本降 70%、分钟级响应的确定性回报。
采购是理性决策:对于绝大多数追求数据敏捷与业务价值的企业,采购经过大规模复杂场景验证的 NoETL 自动化指标平台,是规避风险、加速见效的最优路径。

