智能制造数据资产瘦身指南:三步实现 TCO 最优,释放 50% 成本
摘要
面对海量质检数据与严苛的长期保存合规要求,智能制造企业正陷入数据存储成本高昂、分析效率低下的困境。本文提出一套融合“湖仓一体”与“AI 自动化数据管理”趋势的现代化数据资产瘦身方法论,通过引入 NoETL 语义编织技术,从架构重构、智能治理到敏捷服务三个步骤,系统性解决数据冗余、口径混乱与响应迟缓三大痛点,帮助企业实现总体拥有成本(TCO)降低 30%-50%,并释放超过 1/3 的服务器资源。本文面向制造业的数据架构师、CDO 及 IT 主管,提供一套可量化、可执行的实践指南。
前置条件:诊断你的“数据肥胖症”
在采取任何“瘦身”行动前,必须清晰量化当前数据资产的“肥胖”程度。对于智能制造企业,尤其是涉及精密制造(如半导体、汽车零部件)的领域,数据成本困局通常表现为三大核心症状,其根源在于传统的“烟囱式”宽表开发模式。
- 量化冗余:存储空间的“隐形浪费”
行业观察普遍指出,企业数据湖仓中的数据冗余平均在 5 倍以上。这并非危言耸听。以碳化硅衬底龙头天岳先进的实践为例,其单个厂区年增质检图片文件数量达 数亿至10亿+ 级别,按《IATF16949汽车行业质量管理体系标准》要求保存 15 年以上,数据总量将达 数百亿文件、数十 PB 的惊人规模。传统模式下,为满足不同报表需求,同一份 DWD 明细数据被反复加工成多个物理宽表(ADS 层),导致存储成本呈几何级数增长。
- 识别混乱:指标口径的“诸侯割据”
业务部门抱怨数据“不准”,根源在于指标逻辑被分散定义在物理表、ETL 脚本、BI 报表等各处。例如,“生产线 OEE(设备综合效率)”在 MES 系统、质量分析平台和总经理驾驶舱中可能存在三种不同的计算逻辑(停机时间定义、计划时间范围等),形成“同名不同义”的口径之困。这不仅影响决策质量,更在数据回溯和审计时带来巨大风险。
- 评估迟缓:需求响应的“周级排期”
当业务人员提出一个新的分析维度(如“按新供应商批次分析缺陷率”)时,传统流程需要数据团队重新设计宽表、编写 ETL 任务、进行数据验证,整个周期往往长达 数周。这种响应速度在快节奏的制造业竞争中,意味着错失质量改进和成本优化的黄金窗口期。
第一步:架构重构——从“物理宽表”到“虚拟业务事实网络”
要根治“数据肥胖症”,必须从源头改变数据生产和消费的架构模式。核心是摒弃为每个报表独立建物理宽表的“烟囱式”开发,转而构建一个基于明细数据的、逻辑统一的虚拟业务事实网络。
- 技术原理:声明式语义编织
这一转变依赖于 语义引擎(Semantic Engine) 的核心能力。它直接在未打宽的 DWD 明细数据层上,通过 声明式策略,由用户在界面配置业务实体间的逻辑关联(Join)。系统据此在逻辑层面构建一个“虚拟明细大宽表”或“虚拟业务事实网络”,而非物理上复制和拼接数据。当查询请求到来时,引擎自动将基于指标和维度的逻辑查询,翻译并优化为对底层明细表的高效 SQL 执行。
- 对比优势:从“固化”到“灵动”
| 维度 | 关键指标 (KPI) | 目标参考值 |
|---|---|---|
| 成本维度 | 存储与计算资源消耗降低百分比 | 30% - 50% |
| 物理宽表/汇总表数量减少率 | > 50% | |
| 效率维度 | 指标开发效率提升倍数 | 10 倍 (如从 1 天 3 个到 1 天 40 个) |
| 业务自助分析需求占比 | > 60% | |
| 质量维度 | 核心业务指标口径一致率 | 100% |
| 智能问数(NL2SQL)准确率 | > 90% |
- 湖仓一体适配:发挥底层架构优势
这种架构与现代化的 湖仓一体 平台天然契合。语义引擎直接对接湖仓中的 DWD 层明细数据,充分利用其 存储与计算分离、弹性扩展的特性。企业无需推翻现有数据底座,即可在其上构建轻量、敏捷的语义层,实现“做轻数仓”。
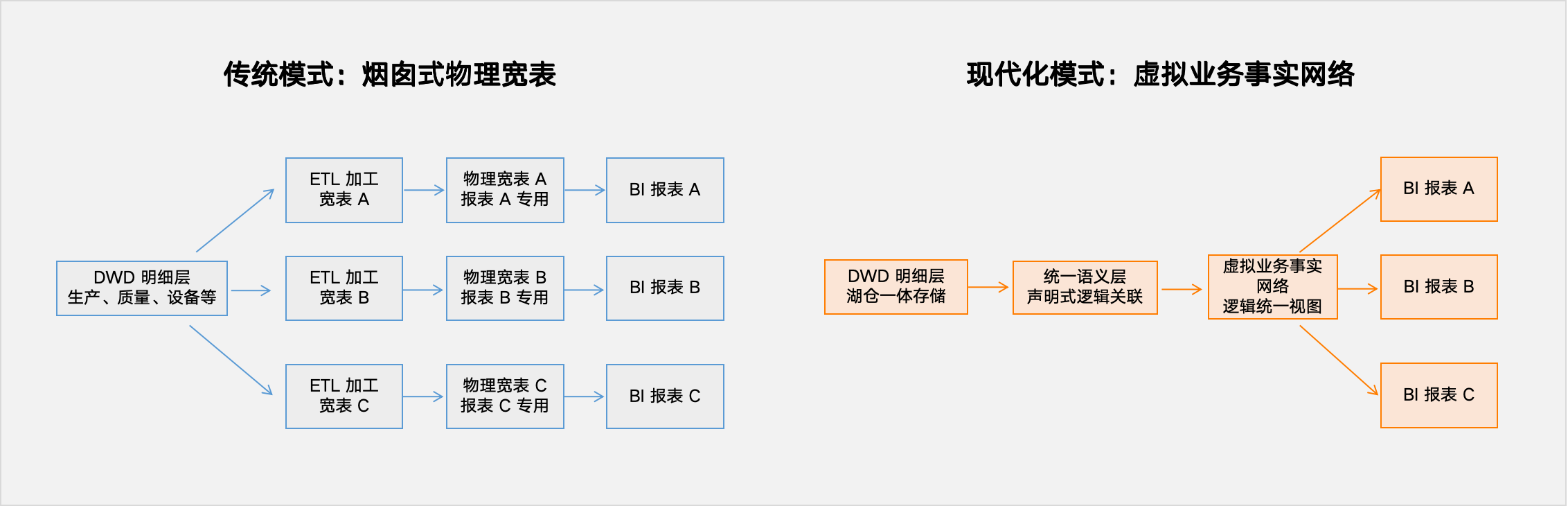
(左右对比:左侧为传统模式,多个 BI 报表对应多个独立物理宽表,数据冗余;右侧为虚拟事实网络,统一语义层逻辑关联 DWD,多个 BI 报表共享同一逻辑层。)
第二步:智能治理——嵌入生产流程的自动化“瘦身”机制
架构重构解决了数据冗余的“存量”问题,而智能治理则通过自动化机制,从“增量”和“使用”环节持续优化,将治理动作从“事后稽核”变为“事中内嵌”。
- 定义即治理:从源头统一口径
在语义引擎中定义指标时,系统会基于指标的逻辑表达式(基础度量、业务限定、统计周期、衍生计算)进行 自动判重校验。如果发现逻辑完全一致的指标,会提示复用,从源头上杜绝“同名不同义”或“同义不同名”的问题,确保企业指标口径 100% 一致。这改变了以往靠文档和人工评审的低效治理模式。
- 智能物化加速:以空间换时间,复用降成本
为了平衡灵活性与查询性能,平台采用 声明式驱动的智能物化加速引擎。用户可以根据业务场景,声明对特定指标组合(如“日粒度-产品线-缺陷数量”)进行物化加速的需求和时效。系统据此自动编排物化任务,并具备关键能力:
* **自动判重与合并**:当多个查询或物化声明逻辑相似时,系统自动识别并合并计算任务,生成共享的物化表,避免重复计算与存储。 * **三级物化机制**:支持明细加速、汇总加速和结果加速,智能路由查询至最优的物化结果,实现亿级数据秒级响应(P90<1s)。 * **透明运维**:物化表的创建、更新、生命周期管理均由系统自动完成,极大减轻运维负担。
- TCO 直接优化:来自实践的量化成效
这种“架构+治理”的组合拳,直接作用于企业的总体拥有成本(TCO)。例如,某头部券商在引入 Aloudata CAN 后,实现了 基础设施成本节约 50%,并 释放了超过 1/3 的服务器资源。其本质是通过消除冗余的物理宽表开发与存储,以及智能复用计算资源,将存算成本从线性增长转变为可控的平缓增长。
第三步:敏捷服务——以统一指标API驱动业务价值变现
“瘦身”的最终目的不是节流,而是为了更好地赋能业务、创造价值。第三步是将治理后的、高质量的数据资产,通过标准、开放的方式,高效、安全地交付给各消费端。
- 统一服务出口:企业指标的“计算中心”
语义引擎平台成为企业指标资产的唯一“注册中心”和“计算中心”。它对外提供标准的 JDBC 接口 和 RESTful API,使得任何需要数据消费的工具或系统,都能通过统一的协议和口径获取数据。这彻底解决了数据出口分散、口径不一的历史难题。
- 赋能业务自助:激活“数据民主化”
业务人员和分析师无需编写 SQL,即可通过简单的拖拽操作,将已定义的“指标”与“维度”进行灵活组合,完成自助分析。例如,质量工程师可以快速分析“近一周各生产线、针对某新物料供应商的缺陷类型分布”。这种模式将大量常规分析需求从 IT 部门释放,显著提升业务响应速度,某央国企实践表明,业务自助可完成 80% 的数据查询和分析需求。
- 原生 AI 适配:根治幻觉的智能问数
面对 AI 浪潮,传统的“NL2SQL”方式因直接面对杂乱物理表而幻觉风险高。基于语义引擎的 “NL2MQL2SQL” 架构提供了更优解:
* **流程**:用户自然语言提问 → LLM 进行意图理解,生成结构化的指标查询语言(MQL,包含Metric, Filter, Dimensions) → 语义引擎将 MQL 翻译为 100% 准确的优化 SQL 并执行。 * **优势**:将开放性的“写代码”问题,收敛为在已治理的指标库中“做选择”的问题,从根本上 **根治幻觉**。同时,结合行列级权限管控,确保 AI 问数的 **安全性** 与 **合规性**。某央国企的智能问数准确率已达 **92%**。
避坑指南:实施“数据瘦身”计划的三大关键决策
成功实施不仅关乎技术选型,更在于正确的组织策略与实施路径。
- 策略选择“三步走”:平滑演进,规避风险
参考 Aloudata CAN 的落地指南,推荐采用资产演进的“三步走”法则:
* **存量挂载**:将逻辑成熟、性能尚可的现有物理宽表直接挂载到新平台,确保历史报表业务 **零中断**。 * **增量原生**:所有新产生的分析需求,必须通过平台的语义层原生定义和响应,从源头 **遏制宽表继续膨胀**。 * **存量替旧**:逐步将维护成本高、逻辑混乱的“包袱型”旧宽表迁移下线,用更优的逻辑模型替代。
- 组织能力建设:“136”协作模式
改变传统IT包揽一切的模式,建立新的协作范式。例如平安证券实践的 “136”模式:10% 的科技人员负责定义原子指标和底层模型;30% 的业务分析师负责配置复杂的派生指标和业务场景;60% 的终端业务用户进行灵活的指标组装和自助分析。这培养了企业的数据民主化文化。
- 规避“重工具轻架构”:选择动态计算引擎
避免仅仅采购一个静态的指标目录或元数据管理工具。这类工具只能“管”不能“算”,依然依赖底层物理宽表。应选择具备 动态计算能力 和 智能物化引擎 的语义平台,真正实现逻辑与物理解耦,从架构上达成瘦身目标。
成功标准:如何衡量你的 TCO 优化成效?
设定可量化的关键绩效指标(KPI),从三个维度评估“数据瘦身”项目的成功。
| 维度 | 关键指标 (KPI) | 目标参考值 |
|---|---|---|
| 成本维度 | 存储与计算资源消耗降低百分比 | 30% - 50% |
| 物理宽表/汇总表数量减少率 | > 50% | |
| 效率维度 | 指标开发效率提升倍数 | 10 倍 (如从 1 天 3 个到 1 天 40 个) |
| 业务自助分析需求占比 | > 60% | |
| 质量维度 | 核心业务指标口径一致率 | 100% |
| 智能问数(NL2SQL)准确率 | > 90% |
FAQ
Q1: 我们已经在使用数据湖/数据仓库,引入“语义引擎”会不会增加架构复杂度和成本?
恰恰相反。语义引擎(如 Aloudata CAN)旨在简化架构。它直接对接您现有的 DWD 层或湖仓,无需新建大量物理宽表(ADS 层),通过逻辑关联和智能物化复用计算,反而能减少数据冗余和重复开发,是降低总体拥有成本(TCO)的关键。
Q2: “数据瘦身”过程中,如何保证历史报表和业务分析的连续性?
推荐采用“三步走”策略。首先,将逻辑稳定、性能尚可的现有宽表直接挂载到新平台,确保历史报表无缝运行。然后,所有新需求通过平台原生定义,遏制宽表膨胀。最后,逐步将维护成本高的旧宽表迁移下线,实现平滑过渡。
Q3: 对于缺乏高级数据人才的制造企业,如何落地这种现代化的数据管理方法?
NoETL 模式的核心价值之一就是降低技术门槛。通过“定义即开发”的零代码配置和“NL2MQL2SQL”的智能问数,业务人员和分析师能承担大量分析工作。企业可以从一个核心业务场景(如生产质量追溯)切入,快速验证价值,再逐步推广,实现“弯道超车”。
Key Takeaways(核心要点)
架构解耦是根本:通过构建基于 DWD 明细层的 虚拟业务事实网络,取代烟囱式物理宽表,从源头上消除数据冗余,这是实现 TCO 优化的架构基础。
治理必须自动化内嵌:将 定义即治理 与 智能物化加速 融入数据生产流程,通过系统自动判重、合并计算任务,在保障口径一致与查询性能的同时,持续优化存算成本。
服务化与 AI 原生是价值放大器:以统一、标准的指标 API 驱动业务自助与 AI 应用,特别是通过 NL2MQL2SQL 架构实现安全、准确的智能问数,将“瘦身”后的数据资产高效转化为业务决策力与创新力。

