为什么公司会有几百个含义模糊的“DAU”指标?深度解析
摘要
指标口径混乱是企业数据治理中最顽固的痛点之一,其根源并非简单的管理疏忽,而是传统“数仓+BI”烟囱式开发模式的必然产物。本文将基于行业权威分析,精确定义“指标口径混乱”的四大要素,并深入剖析导致其泛滥的三大结构性“元凶”。文章面向数据架构师、CDO 及业务分析师,旨在阐明如何通过构建基于 NoETL 语义编织技术的统一指标平台,从根本上解决“数据分析不可能三角”难题,实现指标口径 100% 一致、开发效率 10 倍提升和业务敏捷响应。
开篇:指标混乱不是“病”,而是“症”
“数据孤岛导致的‘同源不同口径’问题日益严重。不同业务系统独立运行,产生的数据没有统一的描述体系。结果就是:明明是同一个‘活跃用户’指标,财务、市场和运营的口径却完全不同。这会直接导致数据驱动的决策不一致。” —— 行业分析报告
当一家企业的数据团队发现,他们维护着数百个名为“DAU”(日活跃用户)或“销售额”的指标,而每个指标的计算逻辑、统计周期或业务限定都略有不同时,这通常不是某个部门或个人的失误。相反,这是传统数据架构模式下的一个必然结果。
在经典的“数仓+BI”模式中,业务需求驱动着漫长的物理开发链路:一个报表需求 → 数据工程师开发 ETL 任务 → 创建特定的物理宽表(DWS/ADS层) → BI 工具连接该宽表生成报表。这种“为特定报表建特定宽表”的烟囱式开发,将指标逻辑固化并分散在了成百上千个物理表中。每一次新的分析视角,都可能催生一张新的宽表和一个“略有不同”的指标版本。这直接导致了数据分析的“不可能三角”:在口径一致、响应敏捷和深度洞察三者之间难以兼得。
精确定义:什么才是真正的“指标口径混乱”?
指标口径混乱并非一个模糊的概念,它特指同一业务术语在不同数据消费场景中,其核心语义要素存在不一致,从而导致决策依据相互矛盾。一个完整的指标定义包含四大语义要素,任何一处的差异都可能导致“混乱”:
基础度量:核心的聚合计算,如
COUNT(DISTINCT user_id)、SUM(order_amount)。统计周期:数据统计的时间范围,如“当日”、“近 7 日滚动”、“本财年至今”。
业务限定:对数据范围的筛选条件,如“状态为‘已支付’”、“用户渠道为‘APP’”。
衍生计算:基于基础度量的二次计算,如同环比、占比、排名。
例如,市场部的“DAU”可能统计所有启动 APP 的设备,而财务部的“DAU”可能只统计完成至少一次有效交易的用户。这不仅仅是“活跃”定义的差异,更是基础度量(是否去重)和业务限定(是否包含交易行为)的双重不一致。
核心要素:导致指标泛滥的三大“元凶”
指标混乱现象是技术架构、组织协作和工具生态三个层面因素共同作用的“完美风暴”。
要素一:烟囱式的物理宽表开发
这是最根本的技术原因。每个分析需求都对应一张(或多张)物理宽表,指标逻辑被硬编码在 SQL 和表结构中。当业务规则变更(如“活跃”定义调整)时,需要追溯并修改所有相关的宽表,成本极高且极易遗漏,导致历史数据对比失真。
要素二:部门墙与协作断层
业务方、数据分析师与数据开发团队之间缺乏统一的协作语言和平台。需求通过邮件、会议口头传递,容易产生歧义。各部门为追求自身效率,在本地数据集或临时查询中定义“自己版本”的指标,形成组织内的“数据方言”。
要素三:封闭的 BI 工具内置指标
主流 BI 工具为提升易用性,内置了指标定义模块。然而,这些指标定义被绑定在特定的 BI 工具前端。当企业使用多套 BI 工具(如总部用 A,业务部门用 B),或需要向 AI 大模型、自建应用提供数据服务时,这些封闭的指标定义无法被复用,形成了新的“工具孤岛”。
常见误区:关于指标治理的四个错误认知
许多企业意识到问题,却采用了错误的方法,反而加剧了困境。
| 误区 | 错误本质 | 导致的后果 |
|---|---|---|
| 误区一:建一个指标字典就够了 | 将指标治理等同于建立静态的元数据目录(Catalog)。 | 目录与计算脱节,业务人员查阅字典后,仍需找开发人员从物理宽表中取数,口径落地依赖人工,无法保证一致性。 |
| 误区二:强制统一所有报表 | 采用行政命令,要求所有部门立即废弃原有报表,使用统一模板。 | 忽视业务敏捷性,引发业务部门强烈抵触,治理行动难以推进,甚至催生更隐蔽的“影子报表”。 |
| 误区三:选择一个 BI 工具统一天下 | 试图通过采购单一 BI 厂商的全套方案来解决所有问题。 | 被单一厂商绑定,丧失技术选型灵活性;无法适应不同场景的多样化需求(如 AI 调用、嵌入式分析)。 |
| 误区四:指标治理是 IT 部门的事 | 认为制定标准、维护口径是数据团队的技术职责。 | 缺乏业务方的深度参与和共识,制定的标准脱离实际业务场景,治理成果无法在业务决策中落地。 |
企业价值:终结指标混乱带来的四大收益
解决指标口径问题,远不止于“统一语言”,它能直接转化为可量化的业务与技术收益。
决策一致:基于同一事实决策,彻底避免部门间因数据“对不上”而产生的无谓争论与信任损耗,提升组织协同效率。
响应敏捷:业务人员通过自助式拖拽分析,无需等待排期,将分析需求响应周期从“天级”压缩至“分钟级”,快速验证业务假设。
洞察深化:突破预建宽表的维度限制,支持对指标进行任意维度、任意粒度的灵活下钻与归因分析,从“描述现象”走向“解释原因”。
成本降低:通过做轻数仓,减少甚至消除大量重复的 DWS/ADS 层物理宽表开发与维护,可释放 30% 以上的服务器计算与存储资源。
案例佐证:某头部股份制银行通过引入统一指标平台,实现了总分行指标口径 100% 一致,数据交付效率提升 10 倍(从 2 周缩短至 1 天),并沉淀了超过 1 万个可复用的标准指标。
评估清单:你的企业是否已陷入指标泥潭?
请用以下 5 个问题快速自检:
同一个核心业务指标(如“销售额”、“利润率”),财务、市场、运营等部门给出的数字是否经常对不上,需要反复核对?
业务部门提出一个新的报表或分析需求,从提出到最终上线,平均排期是否超过 1 周?
业务人员能否在不求助数据团队的情况下,自主、灵活地切换分析维度(如从“按地区看”切换到“按产品品类看”)?
数据团队是否花费大量时间,疲于维护众多业务逻辑相似但略有不同的汇总表、宽表?
当企业引入新的 BI 工具或 AI 智能问数应用时,是否需要数据团队重新定义、开发一套指标?
如果上述问题有两个或以上的答案是肯定的,那么您的企业很可能已经深受指标混乱之苦。
解决方案:基于 NoETL 语义编织的统一指标平台
要根治上述问题,需要从架构层面进行革新,将指标的定义、计算与服务进行逻辑解耦。这正是 Aloudata CAN NoETL 指标平台的核心。
核心理念:定义即开发,定义即服务
平台基于 NoETL 语义编织 技术,允许用户在逻辑层面进行声明式定义:
逻辑关联声明:在 DWD 明细层上,声明业务实体间的关联关系,构建“虚拟业务事实网络”,无需预先物理打宽。
声明式指标定义:通过配置化方式,组合“基础度量、统计周期、业务限定、衍生计算”四大语义要素,零代码定义复杂指标(如“上月高价值用户复购率”)。
智能物化加速:基于用户声明的加速策略,系统自动生成并维护物化视图,查询时智能路由,实现亿级数据秒级响应。
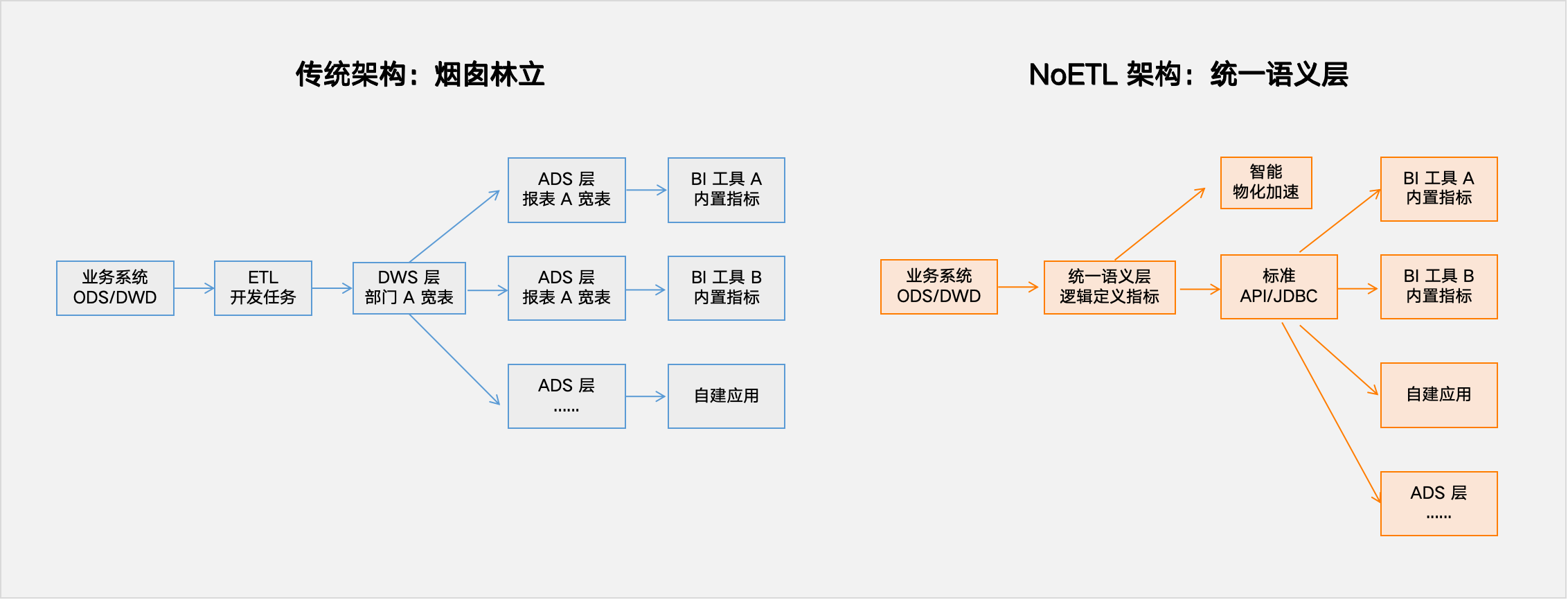
架构对比:从“烟囱林立”到“统一语义层”
传统架构(左):需求驱动,层层物理建模,形成大量 DWS/ADS 宽表,指标逻辑分散且固化。
NoETL 架构(右):统一的语义层直接对接 DWD 明细数据,逻辑定义指标,向上通过标准 API/JDBC 服务各类消费端(BI、AI、应用)。
关键价值:成为 AI-Ready 的数据底座
混乱的指标和元数据是导致 AI 智能问数产生“幻觉”的主因。统一指标平台通过构建高质量的语义知识图谱,为 AI 提供了精准的上下文。
根治幻觉:采用 NL2MQL2SQL 架构。用户用自然语言提问 → LLM 理解意图生成指标查询语言(MQL)→ 平台语义引擎将 MQL 转换为 100% 准确的优化 SQL。
安全可控:所有AI数据请求先经过语义层鉴权,确保符合行列级数据安全策略,实现“先安检,后执行”。
常见问题 (FAQ)
Q1: 我们公司已经用了主流 BI 工具,为什么还需要独立的指标平台?
因为传统 BI 工具的指标定义是内置且绑定在该工具前端的,本质是增强工具粘性的功能模块。当企业存在多套 BI 工具,或需要向 AI 大模型、自建应用、WPS 表格插件等提供数据服务时,这些封闭的指标定义无法被复用。独立的指标平台作为中立的 Headless 基座,提供统一的标准 API,确保全企业“一次定义,处处使用”,口径 100% 一致。
Q2: 统一指标平台和传统数据中台里的指标管理有什么区别?
传统数据中台的指标管理多是“静态目录”,只记录指标元数据(如名称、口径描述),实际计算仍依赖底层人工开发、运维的物理宽表。而现代化的统一指标平台(如 Aloudata CAN)本身是一个动态计算引擎。它基于 NoETL 语义编织技术,直接在 DWD 明细层上通过声明式方式定义指标逻辑,并自动完成计算、物化加速与查询服务,实现了“定义即开发、定义即服务”。
Q3: 实现指标统一,是不是意味着要推翻现有的数据仓库重来?
完全不需要。推荐采用渐进式的 “三步走”资产演进法则:
存量挂载:将现有逻辑成熟、性能稳定的物理宽表直接挂载到平台,快速统一查询出口。
增量原生:所有新的分析需求,直接基于 DWD 明细层在平台上通过声明式定义敏捷响应,遏制宽表继续膨胀。
存量替旧:逐步将维护成本高、逻辑变更频繁的旧宽表迁移至新的语义范式。这实现了平滑演进,而非颠覆式重建。
Q4: 指标平台如何支持现在流行的 AI 智能问数(ChatBI)?
混乱、非结构化的元数据是 AI 产生“幻觉”的根源。指标平台通过构建标准化的语义知识图谱(包含指标、维度、口径、血缘),为 AI 大模型提供了高质量的上下文。采用 NL2MQL2SQL 架构:用户自然语言提问 → LLM 生成基于语义知识的MQL → 平台语义引擎将 MQL 翻译为精准、高效的 SQL → 智能路由至最优物化表或明细层执行 → 返回结果。这从根本上将 AI 生成 SQL 的“开放题”收敛为选择标准指标的“选择题”,实现高准确率。
Q5: 对于数字化初期的企业,直接建设统一指标平台是不是“杀鸡用牛刀”?
恰恰相反,这是实现 “数字化平权” 和弯道超车的战略机遇。传统企业经历了“先乱后治”的痛苦过程。数字化初期的企业可以直接采用最先进的“语义模型驱动”架构,跳过宽表泛滥、口径混乱的阶段,以较低门槛一步到位构建统一、敏捷、标准的数据服务能力,避免未来高昂的治理与重构成本。
Key Takeaways(核心要点)
指标混乱是“症”非“病”:它是传统烟囱式数据开发模式的必然产物,根源在于技术架构,而非管理能力。
治理需解耦逻辑与物理:有效的指标治理必须将业务语义的定义,从物理宽表的开发中解放出来。
统一语义层是核心:基于 NoETL 语义编织技术构建的统一指标平台,能够实现指标的“定义即开发、定义即服务”,成为企业唯一可信的数据事实源。
价值超越降本增效:除了提升开发效率、降低资源成本,更能保障决策一致性、赋能业务敏捷分析,并构成未来 AI 应用不可或缺的 AI-Ready 数据底座。
落地可渐进平滑:通过“存量挂载、增量原生、存量替旧”的三步走策略,企业可以在不影响现有业务的前提下,稳步向现代化数据架构演进。

